딥러닝 기본적인 모델 유형
문제 유형에 대한 방법과 손실 함수를 구분하자(헷갈리기 쉽다.) 특히 OLS와 MSE의 경우

회귀 분석 : 종속 변수와 독립변수의 관계를 도출하는 것
변수들 간의 관계를 파악함으로써 어떤 특정한 변수의 값을 다른 변수들로 설명하고 예측하는 통계적 기법
-> 종속 변수 : 예측하고자 하는 변수
-> 독립 변수 : 종속 변수들을 설명하는 변수
- 종류
- 선형 회귀(Linear Regression)
- 로지스틱 회귀 (Logistic Regression)

선형 회귀 (Linear Regression)
연속적인 숫자(실수 값)를 예측하는 문제
ex) 집값 예측, 온도 예측, 판매량 예측 등
- 종류
- 단순 선형 회귀 (Simple Linear Regression)
- 다중 선형 회귀 (Multiple Linear Regression)
- 다항 회귀 (Polynomial Regression)
단순 선형 회귀 (Simple Linear Regression)
가장 기본적인 회귀 모델로, 1개의 입력 변수(X)와 1개의 출력 변수(Y) 사이의 직선관계를 찾는 회귀 모델
-> 단순 선형 회귀(Simple Linear Regression) 또는 단순 회귀(Simple Regression)라고도 부른다.
- 지도 학습(Supervised Learning)의 한 종류
- 목적 값(반응 변수, Depenent Variable)이 연속형인 경우 사용
- 입력 변수(Feature)가 하나이면서 선형 관계인 경우를 뜻함
- 2D 직선의 형태를 띔
- x = 공부 시간 -> y = 성적
- y = wx + b
- 비선형 관계를 가지게 하는 활성화 함수가 없다

다중 선형 회귀 (Multiple Linear Regression)
여러개의 입력 변수(X)와 1개의 출력 변수(Y) 사이의 직선관계를 찾는 회귀 모델
-> 다중 선형 회귀(Multiple Linear Regression) 또는 다중 회귀(Multiple Regression)라고도 부른다.
- 입력 변수(Feature)가 여러개이면서 선형 관계인 경우를 뜻함
- 3D 평면 or 고차원 형태를 띔
- x1 = 공부 시간, x2 = 수면 시간 -> y = 성적
- y = w1x1 + w2x2 + w3x3 + .......+ b
- 비선형 관계를 가지게 하는 활성화 함수가 없다
다항 회귀(Polynomial Regression)
-> OLS 기법을 통해서 각 함수의 계수를 구함
차수가 2차 이상인 독립 변수(X)와 1개의 출력 변수(Y) 사이의 곡선 관계를 찾는 회귀 모델
단순 선형 회귀로 해결할 수 없는 곡선 관계(Non-linear Relationship, 비선형 관계)를 찾는 문제

- 비선형 관계를 가지게 하는 활성화 함수 사용

최소 제곱 추정량 (OLS : Ordinary Least Square estimation)
-> 선형 회귀 계수(파라미터)를 구하는 방법(과정)
회귀 선이 데이터를 가장 잘 표현하도록 가중치(w)를 찾는 방법
-> 오차 (Residual : 잔차, 실제값 - 예측값) 의 제곱합을 최소화하는 방식
MSE가 있는데 이것은 왜 있는 것일까?
MSE란 손실 함수를 의미하고 OLS는 MSE를 이용해서 함수의 계수를 구하기 위한 과정 즉 방법을 뜻하는 것이다.
-> 즉, OLS는 MSE를 최소화하는 파라미터를 찾는 알고리즘
MSE는 OLS가 최소화하고자하는 목적 함수(Loss)

- 최소 제곱법의 기능
- 오차의 제곱을 최소화하는 방식으로 최적의 회귀선을 찾음
- 경사 하강법(Gradient Descent) 또는 행렬 연산을 이용하여 최적화 가능


로지스틱 회귀(Logistic Regression) : 선형 결합으로 이루어진 모델(Y = WX+ B)를 이용하여 어떤 사건을 분류하거나 예측하는 데 사용하는 기법(방법 == 과정)
-> 분류 : 종류를 예측하는 것
- 종류
- 이진 분류(Binary Classification)
- 다중 분류(Multinomial Classification)
분류 모델 성능 평가 지표(Accuracy, Precision, Recall, F1 score 등)
분류 모델(Classifier)을 평가할 때 주로 Confusion Matrix를 기반으로 Accuracy, Precision, Recall, F1 score를 측정한다.
- Confusion Matrix(혼동 행렬, 오차 행렬)
- 분류 모델의 성능을 측정하는데 자주 사용되는 표로 모델이 두 개 이상의 클래스를 얼마나 헷갈려하는지 알 수 있다.

- T(True) : 예측한 것이 정답
- F(False) : 예측한 것이 오답
- P(Positive) : 모델이 positive라고 예측
- N(Negative) : 모델이 negative라고 예측
- TP(True Positive) : 모델이 Positive라고 예측했는데 실제로 정답이 positive (정답)
- TN(True Negative) : 모델이 Negative라고 예측했는데 실제로 정답이 negative (정답)
- FP(False Positive) : 모델이 Positive라고 예측했는데 실제로 정답이 negative (오답)
- FN(False Negative) : 모델이 Negative라고 예측했는데 실제로 정답이 Positive (오답)
- Accuracy(정확도) -> ACC
- 모델이 전체 문제 중에서 정답을 맞춘 비율
- 하지만 데이터가 불균형 할때 (ex. positive : negative = 9:1)는 Accuracy만으로 제대로 분류했는지는 알 수 없기 때문에 Recall과 Precision을 사용한다.
- 0~ 1 사이의 값을 가지며, 1에 가까울수록 좋다

- Precision(정밀도) = PPV(Positive Predictive Value)
- 모델이 Positive라고 예측한 것들 중에서 실제로 정답이 Positive인 비율
- 실제 정답이 negative인 데이터를 positive라고 잘못 예측하면 안되는 경우에 중요한 지표가 될 수 있다.
- Precision을 높이기 위해선 FP를 낮추는 것이 중요하다
- 0 ~ 1 사이의 값을 가지며 1에 가까울 수록 좋다.

- Recall(재현율) = Sensitivity(민감도) = TPR(True Positive Rate)
- 실제로 정답이 positive인 것들 중에서 모델이 positive라고 예측한 비율
- 실제 정답이 positive인 데이터를 negative라고 잘못 예측하면 안되는 경우에 중요한 지표가 될 수 있다.
- Recall 을 높이기 위해선 FN을 낮추는 것이 중요하다
- 0 ~ 1 사이의 값을 가지며, 1에 가까울 수록 좋다.

- F1 score
- Recall과 Precision의 조화 평균
- Recall과 Precision은 상호 보완적인 평가지표이기 때문에 F1 score을 사용한다.
- Recall과 Precision이 한쪽으로 치우쳐지지 않고, 모두 클 때 큰 값을 가진다
- 0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
- 이진 분류 문제에서 데이터의 클래스 비율이 극단적으로 다른 경우 적합한 평가지표

- Error Rate(오분류율)
- 모델이 전체 데이터에서 잘못 맞춘 비율

- Specificity(특이도) = TNR(True Negative Rate)
- 실제 정답이 negative인 것들 중에서 모델이 negative라고 예측한 비율

- Fall out(위양성률) = FPR(False Positive Rate)
- 실제 정답이 negative인 것들 중에서 모델이 positive라고 예측한 비율

- 평가 지표 선택
- 정밀도를 중시 : 거짓 양성이 문제일때 (ex. 스팸 필터)
- 재현율을 중시 : 거짓 음성이 문제일때 (ex. 암 진단)
- F1 - 점수 : Precision과 Recall이 모두 중요할 때
- ROC-AUC : 확률 기반 모델의 전반적인 성능 평가
https://ai-creator.tistory.com/578 ->성능 평가 지표 정리본
https://ai-creator.tistory.com/579 -> 다중 분류일때의 성능 평가 참고 자료
ROC -AUC 그래프 분석
다양한 threshold에 대한 이진 분류기의 성능을 한번에 표시한 것
-> 좌상단에 붙어 있는 커브가 더 좋은 분류기를 의미한다.
-> x축 : 모델이 Positive라 예측했지만 실제로는 Negative인 경우(오답)
-> y축 : 모델이 Positive라 예측했고, 실제 정답도 Positive인 경우(정답)




https://angeloyeo.github.io/2020/08/05/ROC.html ->ROC 그래프 참고 자료
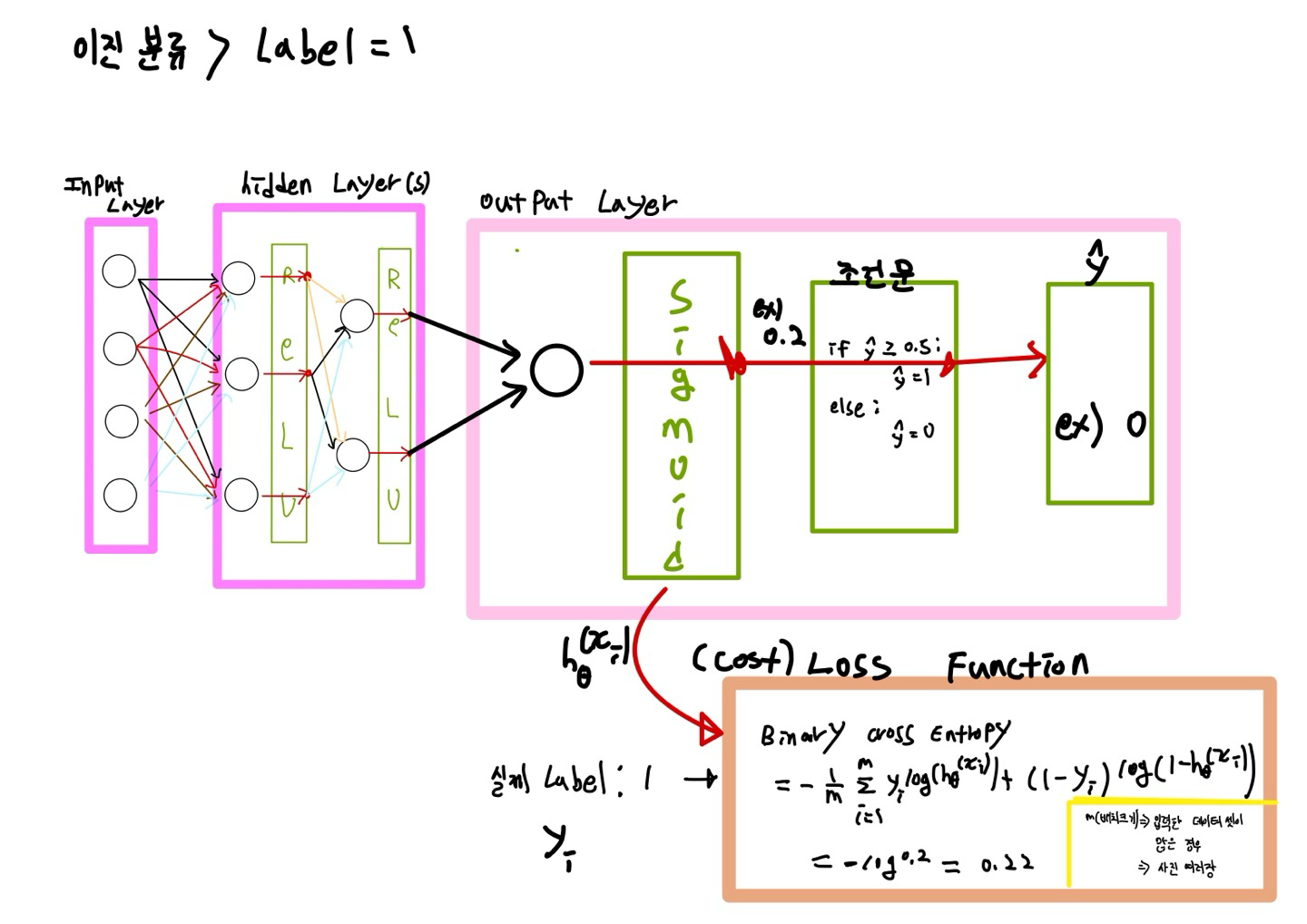
이진 분류 (Binary Classification)
입력 값에 따라 모델이 분류한 카테고리가 두가지인 분류 알고리즘
->집합의 요소를 두개의 그룹(각각을 클래스라 한다.) 중 하나로 분류하는 작업
-> 참(True,1)/ 거짓(False,0)
-> 여러 개의 독립 변수와 1개의 종속 변수를 가진 신경망 구조( 즉, 출력 노드는 하나)
- 지도 학습
- Target(반응 변수)이 두 개의 클래스로 분류
- 시험: Pass/Fail
- 종양 : 악성/ 양성
- 손실 함수는 Binary Cross Entropy Loss를 사용
- 출력층에서의 활성화 함수로 Sigmoid 사용


다중 분류 ( Multinomial Classification )
입력값에 따라 모델이 분류한 카테고리가 세가지 이상인 분류 알고리즘
-> 타겟(target, = 종속 변수)이 가지는 값에 대응되는 데이터의 집합을 클래스 혹은 레이블이라고 함
- 지도 학습
- Target(종속(반응) 변수)이 다중 분류인 경우
- 등급 : 상/ 중 / 하
- 신용 등급 : 매우 양호/ 양호/ 보통/ 불량/ 매우 불량
- 붓꽃의 종류 : Setosa/ Versicolor/ Virginica
- 다중 분류 모델은 여러 개의 출력 값을 가지며 각각의 출력 값은 대응되는 타겟(클래스)와 매칭 될 확률을 의미함
- 출력 층에서 활성화 함수로 Softmax 를 사용함로써 확률 값들로 바꿔줌
- 그 확률 값들을 one-hot encoding 기법을 사용해서 범주형 데이터로 탈바꿈
- one- hot encoding : 데이터 값들 중 확률이 가장 높은 값만 1로 남겨두고, 나머지 값들은 0으로 세팅하는 과정
- 범주형 데이터와 데이터가 연속적인 특징을 갖지 않는 수치형 데이터에서 많이 사용되는 기법
- 왜 사용하는가?
- 텍스트 형태의 범주형 데이터를 컴퓨터가 이해하려면 해당 데이터를 숫자 데이터로 바꾸어줘야한다.
- 이 과정을 통해 컴퓨터가 숫자를 통해 해당 범주형 데이터를 인지할 수 있게 되었지만 숫자 간의 크기(순서) 관계가 생겨버려서 컴퓨터가 범주형 데이터들을 연속적인 값처럼 오해하게 되는 문제가 발생한다.
- 그래서 연속성이 없다는 것을 확실히 하기 위해서 원 핫 인코딩(One-Hot Encoding)이라는 기법을 사용한다.
-> 각각의 데이터 범주에 대해 연속성 또는 순서에 대한 의미가 사라짐
- one- hot encoding : 데이터 값들 중 확률이 가장 높은 값만 1로 남겨두고, 나머지 값들은 0으로 세팅하는 과정

- 손실 함수는 Categorical Cross Entropy Loss를 주로 사용
- pytorch에서 CrossEntropyLoss 함수 내부는 softmax(정확하게는 LogSoftmax)와 NLLLoss가 합쳐진 형태다
- NLLLoss(Negative Log Likelihood)는 input 값에 대해 그냥 음의 값만을 취해주는 것
- input 값은 log(P)가 들어온다. 즉, LogSoftmax의 확률 값이 input임
- Cross Entropy Loss = Softmax + log + NLLLoss
- Cross Entropy Loss = LogSoftmax + NLLLoss
- pytorch에서 CrossEntropyLoss 함수 내부는 softmax(정확하게는 LogSoftmax)와 NLLLoss가 합쳐진 형태다


-> 확률 값이 클 수록 오차가 줄어든다.( 0~1 )

-> h는 softmax 활성화 함수를 통해서 확률값으로 변환된 값이 들어간다.
->y 는 실제 값이 one- hot encoding을 거쳐서 나온 결과물이 들어간다.


-> 즉 학습시킬때는 정답 Label을 one-hot encoding해서 손실함수를 구한다.
-> 학습이 끝난 후에는 잘 학습이 되었는지 확인을 위해 순전파 과정 마지막에 one-hot encoding을 적용한다.

5. 다중분류 문제에서 클래스 불균형 문제를 완화하기 위한 방법으로 적합한 것은 무엇인가요? 모두 정답
① Oversampling
② Data Augmentation
③ Class Weighting
④ Under-samplin
참고 문헌:
https://076923.github.io/posts/Python-pytorch-13/
https://ai-creator.tistory.com/579
https://white-joy.tistory.com/9 -> 이진 분류 평가지표