CNN 발전 과정(1)
Computer vision에서의 문제 4가지

- Semantic segmentation : 이미지에 있는 모든 픽셀을 해당하는 (미리 지정된 개수의) class로 분류하는 것
-> 이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에 dense prediction이라고도 부른다.
-> 주의 할 점 : 같은 class의 instance를 구별하지 않는다.
-> 픽셀 별로 분류만 하는 것

- Classification + Localization : Single object에 대해서 object의 위치를 bounding box로 찾고(Localization), 클래스를 분류하는 문제(Classification)
-> 하나의 물체에 대해서 위치 탐색 및 분류

- Object Detection : Multiple objects에서 각각의 object에 대해 classification + Localization을 수행하는 문제
-> 다수의 물체 위치 탐색 및 분류
-> YOLO, R-CNN 등의 모델

- Instance Segmentation : Object Detection과 유사하지만 다른 점은 object의 위치를 bounding box가 아닌 실제 edge로 찾는것
-> 다수의 물체 위치 탐색 및 분류 + instance 구별


LeNet-5 -> CNN이 만들어진지는 조금 되었지만 CNN을 실제로 적용한 모델이라는 점에서 중요
- 필기체 인식 모델
- AT & T 벨 연구소에서 개발됨
- 기본적인 CNN 구조의 기초가 된 모델

나오게 된 배경(이전 방법에서의 문제점)
- Hand-designed feature extractor는 제한된 특징만 추출
- 전에는 Hand-designed feature extractor 즉, 사람이 수동으로 중요한 정보를 정의하고 추출하는 방식이었기 때문에 제한된 학습이 이루어 질 수 밖에 없었다.
-> 좋은 학습은 feature extractor 그 자체에서 학습이 이루져야한다고 말함
- 전에는 Hand-designed feature extractor 즉, 사람이 수동으로 중요한 정보를 정의하고 추출하는 방식이었기 때문에 제한된 학습이 이루어 질 수 밖에 없었다.
- 너무 많은 매개 변수를 포함한다.
- Fully-Connected Layer(FC)의 경우 너무 많은 가중치를 가지며, 이미지가 이동했을때 가중치의 의미를 잃게 된다.
-> 전에는 FC layer들 만으로 학습하게 될 경우 너무 많은 parameter를 생성해야됨
- Fully-Connected Layer(FC)의 경우 너무 많은 가중치를 가지며, 이미지가 이동했을때 가중치의 의미를 잃게 된다.
- 입력 값의 topology(형태나 구조)가 완전히 무시된다.
- 이미지는 2D 구조를 가지고 있으므로 인접한 픽셀들은 공간적으로 매우 큰 상관 관계가 있다.
-> FC에서는 이러한 공간적인(spatial) 정보 또는 형태나 구조가 사라지기 때문
- 이미지는 2D 구조를 가지고 있으므로 인접한 픽셀들은 공간적으로 매우 큰 상관 관계가 있다.
LeNet-5 구조

input -> Conv(C1) -> Avg pooling(S2) -> Conv(C3) -> Avg Pooling(S4) -> Conv(C5) -> Fully-connected(F6) -> output
input -> Conv(C1) : 입력 이미지를 5 x 5 kernel *6(필터 개수) 필터와 컨볼루션 연산을 해준다.
-> 그 결과 28 x 28 * 6 장의 특성 맵이 생성된다.
-> (32-5) +1 = 28
-> 활성화 함수 : Sigmoid
-> 파라미터 개수 : 156( weight :150 / bias : 6)
Conv(C1) -> S2 : 6장의 28 x 28 특성 맵에 대해 2 x 2 커널을 stride 2로 서브 샘플링(subsampling) 즉, Average Pooling을 진행한다.
-> 그 결과 6장의 14 x 14 사이즈의 특성맵으로 축소된다.
-> (28-2)/2+1 = 14
-> 활성화 함수 : Sigmoid
-> 파라미터 개수 : X
S2 -> C3 : 아래 표와 같이 입력으로 6장의 14 x 14 사이즈의 특성맵이 있고 X 표시 된 입력 이미지를 합치고 각 합친 이미지 수에 따른 5 X 5 x n(이미지 수) 필터와 컨볼루션 해주어 총 16개의 10 x 10 특성 맵을 얻는다.
-> C3 Layer에서의 Convolution은 기존의 합성곱 방식과 다르다.
-> 부분 연결 방식
-> 활성화 함수 : Sigmoid
-> 파라미터 개수 : 1516 (weight :1500 / bias : 16)
-> (5*5*3*6 + 5*5*4*(6+3) + 5*5*6) + 16 =1516
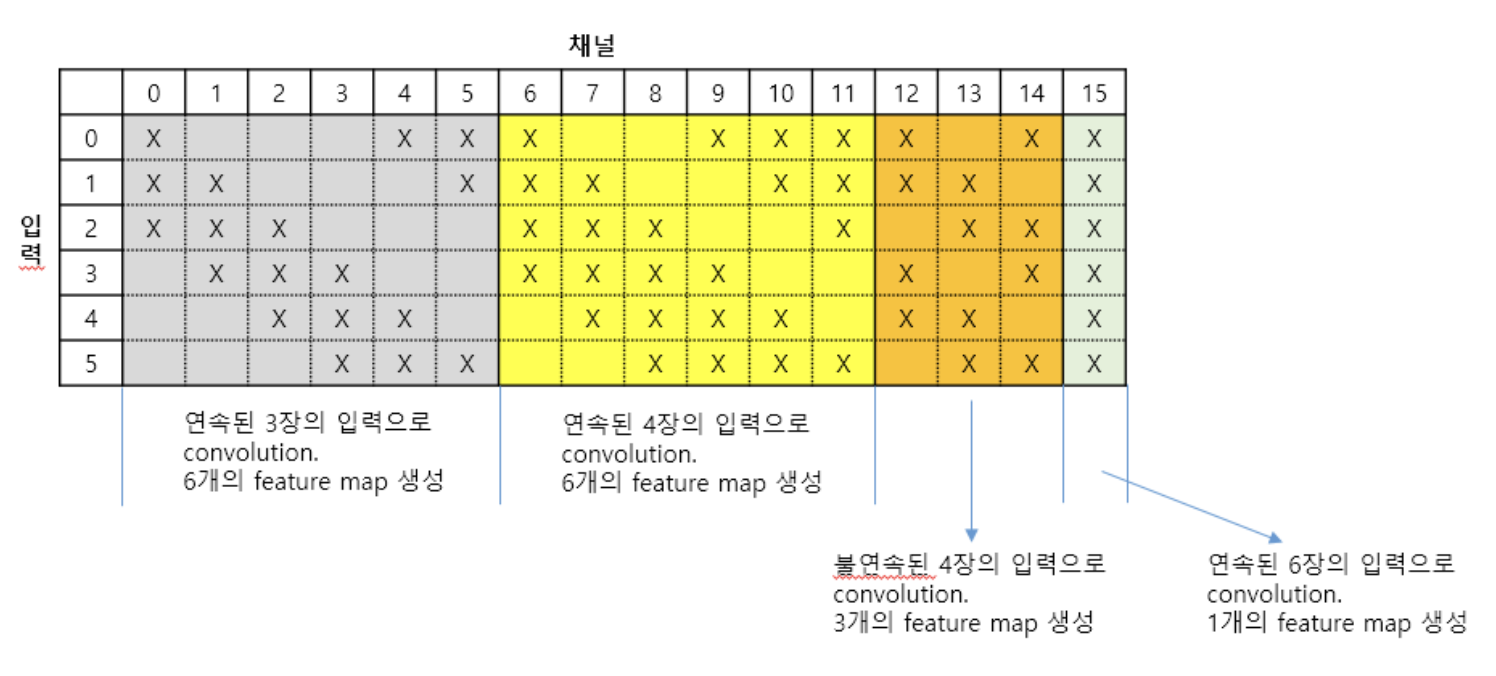



위와 같은 방식으로 16장을 뽑아낸 것이다.
왜 이런 방식으로 C3을 설계한 것일까?
만약 전부 연결되면 중앙을 기준으로 대칭되기 때문에 같은 필터들이 만들어질 확률이 높아지며 역전파 과정에서 weight와 bias가 비슷하게 업데이트가 되기 때문 그러다 보니 같은 weight를 가져도 connection이 달라지면 weight가 업데이트 되는 경향이 달라져 대칭성이 깨져 다양한 필터들을 만들어 낼 수 있기때문에
-> 모든 채널에 대해서 동일한 5 x 5 필터를 적용한다면 필터들이 서로 유사하거나 대칭적인 특징을 학습할 가능성이 높아져서
Feature Map 간의 대칭성을 깨고, 다양한 특성을 가진 Feature Map을 생성해 내기 위해서 이런 방식을 사용하였다.
-> 모든 채널이 비슷한 방식으로 학습되기 때문
-> 이 시기에는 드롭 아웃(Dropout), 배치 정규화(Batch Normalization) 등의 기법이 없었기 때문
Conv(C3) -> Avg Pooling(S4) : 16장의 10 x 10 특성 맵에 대해서 Average Pooling(2 x 2 필터, stride)을 진행
-> 그 결과 16장의 5 x 5 특성 맵으로 축소시킨다.
-> (10-2)/2+1 = 5
-> 활성화 함수 : Sigmoid
-> 파라미터 개수 : X
Avg Pooling(S4) -> Conv(C5) : 16장의 5 x 5 특성맵에 대해서 120개의 5 x 5 x 16 사이즈의 필터와 컨볼루션 해준다.
-> 그 결과 120개의 1 x 1 특성맵이 나오게된다.
-> (5-5) +1 = 1 (이것이 120개 있는 것)
-> 활성화 함수 : Sigmoid
-> 파라미터 개수 : 48120 ( weight : 48000 / bias : 120)
Conv(C5) -> Fully-connected(F6) : 120개의 1 x 1 커널을 펼쳐서 FC layer로 만들고, 84개의 노드(unit)에 연결한다.
-> 활성화 함수 : tanh
-> 파라미터 개수 : 10164
-> (120*1 +1)* 84 = 10164
Fully-connected(F6) -> output : 10(0~9 까지의 숫자 이므로) 개의 노드들로 출력층에 분류 되게 된다.
-> 10개의 출력을 통해서 0~9 중 하나의 이미지라고 분류를 해냄 -> 젤 높은 확률을 해당 숫자로 판단
-> Logsoftmax를 사용해도 됨
-> 총 파라미터 개수 : 156 + 1516 + 48120 + 10164 + (84 +1) * 10 = 60806개

->이와 같이 순전파가 이루어지게 되고
Loss Function으로는 MSE(평균 제곱 오차)를 이용하였다.
Optimizer는 아무거나 사용해도 된다.
LeNet-5 의 특징
1. 수용 영역(receptive field) : CNN의 깊은 층으로 갈 수록 아래 그림처럼 한 픽셀이 담고 있는 정보는 많다.

2. 가중치 공유 (shared weight) : 하나의 filter로 이미지를 돌아다니며 계산한다.
https://www.youtube.com/watch?v=28SQ9wJ74vU -> LeNet-5 논문 리뷰 유튜브 영상
https://deep-learning-study.tistory.com/368 -> LeNet -5 블로그