AI 정리
GAN(Generative Adversarial Networks)
dawon-project
2025. 3. 31. 23:42
GAN : 서로 다른 두 개의 네트워크를 적대적(adversarial)으로 학습시키며 실제 데이터와 비슷한 데이터를 생성(generative)해내는 모델
-> Discriminator(판단자)는 Supervised Learning(지도 학습)
-> Generator(생성자)는 Unsupervised Learning(비지도 학습)

GAN Architecture
- Generator(G) : 임의의 노이즈 벡터로부터 가짜 데이터 생성
- Discriminator(D): 입력이 진짜(real)인지 가짜(fake)인지 판별
- G는 D를 속이려고 학습하고 , D는 G를 잡아내기 위해 학습
-> 게임 이론적 최적화

-> 생성자는 내가 만든 지폐는 위조 지폐가 아니야라고 말하고 판단자는 생성자 너꺼 위조지폐야 하면서 계속 경쟁을 하다 결국엔 생성자가 위조지폐를 진짜 지폐라고 속이게 만드는 이미지를 생성해내는 과정에 이르는 것
Vanillar GAN 구조
- 가장 기본적인 GAN 형태
- 노이즈 z -> Generator -> fake Image
- Discriminator는 Fake vs Real 판별
- Loss : G는 D의 판별 실패 유도, D는 올바른 판별 학습

=> 파라미터 미분을 따로 수행할 수있도록 생성자와 판별자의 최적화함수들을 따로 정의해서 사용해야함



GAN Loss Function -> 근본은 BCELoss이다.
- Discriminator Loss : Real은 1, Fake는 0에 가깝도록 분류
- Gererator Loss : Fake 이미지를 Real로 착각하도록 학습

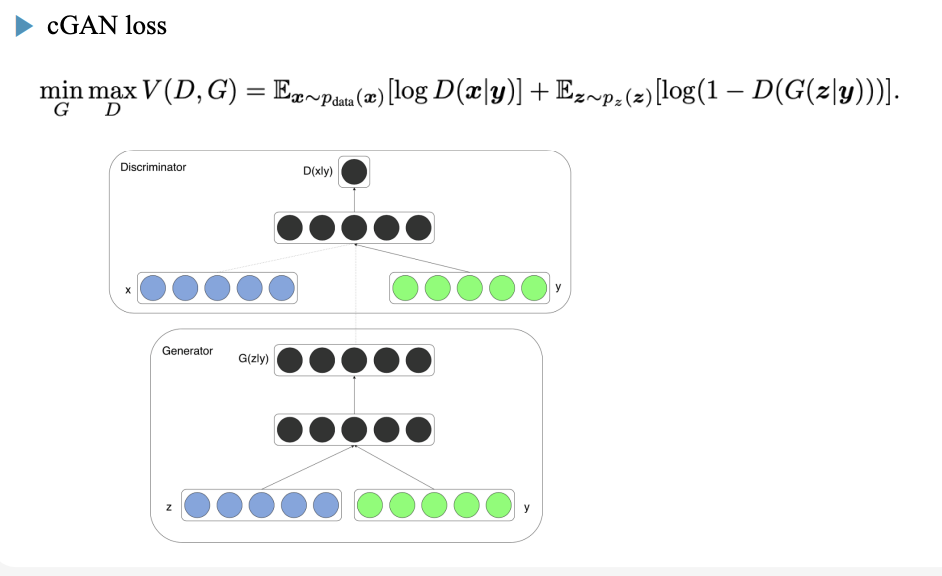
cGAN(conditional GAN)
- 조건부 GAN : 특정 레이블이나 정보를 조건으로 주고 생성
-> 조건 y를 입력에 추가하여 조건 제어된 생성 가능 - ex) "3이라는 숫자 생성" , "여자 얼굴 생성" 등
-> 기본적인 Vanilla Gan은 어떤 이미지가 나올지 예측할 수 없으나 CGAN은 어떠한 형태의 이미지를 만들라고 한정시켜서 학습시키는 형태

cGAN Loss Function
- 기본 GAN의 loss에 조건 정보 y를 추가한 형태
- Generator와 Discriminator 모두 condition y 를 입력으로 사용
GAN계열의 한계 및 단점 => AI가 판단자를 속이는 구역을 알아서 꼼수로 학습해서 정답이 아닌것 같은 그림이 정답이라 말하게 만드는 상황이 생긴다.
<문제점>
- 고해상도 생성 어려움 -> 초기 GAN은 64 x 64 정도로 작은 이미지 ex) MNIST
- 학습 불안정 -> G와 D의 경쟁이 균형이 맞지 않으면 collapse
- Density estimation 어려움 -> 생성된 분포의 확률 밀도를 명확히 알기 어려움
- 평가 지표 부족 -> 생성된 이미지 품질 평가가 주관적일 수 있음
- 노이즈와 이미지 간의 매핑 해석 어려움 -> 어떤 z가 어떤 이미지인지 설명 불가

DCGAN(Deep Convoltuion GAN) : Vanilla GAN을 CNN 기반으로 확장한 구조
- ConvTranspose2D 사용(업샘플링)
- BatchNorm, LeakyReLU 등 활용
- 더 안정적인 학습과 고해상도 이미지 생성 가능
-> 하지만 여전히 고해상도 이미지 생성이 어려움



training 방법 자체는 GAN계열은 동일하나 어떤 Layer를 쓰느냐에 따라 모델 구조가 달라진다

DCGAN의 벡터 연산 특징
- latent vector(z)의 연산으로 의미 있는 조작 가능
ex) 남자 + 안경 - 여자 = 남자 안경 쓴 얼굴(벡터의 의미적 조작)
GAN을 활용한 응용 기술
- 사람, 동물, 등 가짜 이미지 생성
-> 실재하지 않는 사실적인 이미지를 생성할 수 있다. - 다른 스타일 이미지로 변환
- 상상이나 개념을 이미지로 번역
- 낙서 같은 의미론적 이미지를 실제 사진으로 변환할 수 있다.

