pandas
- 데이터 분석과 조작을 위한 Python 라이브러리
- CSV 파일 등의 데이터를 읽고 원하는 데이터 형식으로 변환
- csv(comma separated values) 파일 : 데이터를 쉼표로 구분한 파일
- CSV 파일 등의 데이터를 읽고 원하는 데이터 형식으로 변환
- 주요 자료구조
- Series : 1차원 배열, 라벨이 있는 데이터
- DataFrame : 2차원 테이블 구조, 라벨이 있는 행과 열
- 테이블이란? 가로(행)과 세로(열)로 정렬된 데이터 집합
- 행(row, 로우)
- 열(column, 컬럼)
- 테이블이란? 가로(행)과 세로(열)로 정렬된 데이터 집합
- 설치 및 import
- pip install pandas
- import pandas as pd
- pip란?
- Python 패키지 관리자(Package Installer for Python)
- Python 라이브러리를 설치 및 관리 위해 사용
- 주요 명령어 (터미널 명령 프롬프트에서 실행)
- 패키지 설치 : pip install <패키지명>
- 패키지 제거 : pip uninstall <패키지명>
- 설치된 패키지 목록 확인 : pip list
- pip란?
- Series 자료 구조 생성
- 리스트 데이터를 사용한 Series 객체 생성
- 따로 인덱스를 지정하지 않았다면 0부터 시작하는 정수 값으로 인덱싱 됨
- 딕셔너리 데이터를 사용한 Series 객체 생성
- key를 인덱스 값으로 사용
- 리스트 데이터를 사용한 Series 객체 생성

- DataFrame 자료 구조 생성
- 중첩 리스트 데이터를 사용한 DataFrame 객체 생성
- 컬럼 명을 옵션으로 지정 가능
- 딕셔너리 데이터를 사용한 DataFrame 객체 생성
- key를 컬럼 명으로 사용
- 중첩 리스트 데이터를 사용한 DataFrame 객체 생성

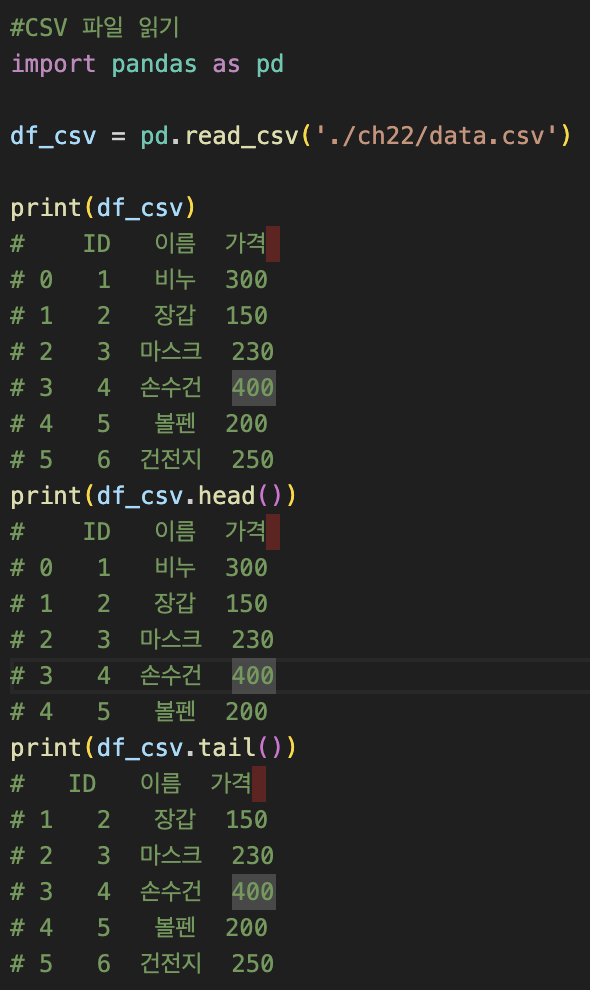
- CSV 파일 읽기
- CSV 파일 구조
- 줄 바꿈으로 구분되는 1개 이상의 행(레코드)으로 구성
- 각 행은 1개 이상의 열(필드)로 구성
- 필드는 큰 따옴표로 둘러 싸도됨(단, 통일성이 있어야함
- CSV 파일 구조

-
- Excel 파일 읽기
- openpyxl 모듈 필요
- 파이썬 표준 모듈이 아니므로 추가 설치 필요
- pip install openpyxl
- 실행 명령어
- ex) df_xl = pd.read_exec('D:/rokey/ch19/data.xlsx')
- openpyxl 모듈 필요
- Excel 파일 구조
- 파일을 북(book)이라고 함
- 하나의 북 내부에는 여러 개의 시트(sheet)가 존재
- 각 시트는 행(row)와 열(column)을 가진 2차원 셀(cell)로 구성
- Excel 파일 기본 생성
- 마이크로소프트 엑셀 프로그램을 통한 생성
- 데이터 탐색
- head() : 데이터 상위 5개 행을 보여주는 함수
- tail(): 데이터 하위 5개의 행을 보여주는 함수
- info() : 데이터 요약 정보를 보여주는 함수
- describe() : 기술 통계를 보여주는 함수
- sample(x) : Pandas DataFrame에서 임의의 샘플(랜덤한 행)들을 선택하는 함수
- sample(2) : 데이터 중에 랜덤으로 2개의 샘플을 선택
- sample(frac =0.5) : 데이터의 50%를 랜덤하게 선택
- 데이터 조작
- 데이터 선택 및 필터링 방법
- 인덱싱을 통한 열 또는 행 선택 ex) df['Name']
- 인덱싱한 것에 조건을 걸어 조건 필터링
- ex) df[df['Age'] >30]
- sort_values(by= 기준열) : 특정 열의 값을 기준으로 정렬할 때 사용
- 열 추가 및 삭제
- 열 추가 -> 인덱싱
- df['Salary'] = [ 50,60,50]
- 행 추가 -> loc[] 함수 사용
- df.loc[len(df)] =[4, 'David', 40, 80000]
- 행 삭제 -> drop() 함수 사용
- df.drop(1) # 1 번 인덱스 행 삭제
- 열 추가 -> 인덱싱
- 데이터 선택 및 필터링 방법
- Excel 파일 읽기




- concat() : DataFrame 행 연결
- concat() 함수 매개변수는 데이터 프레임 리스트형
NaN(Not a Number)
- 결측값(NA, Not Available) 표현
- 정의되지 않은 값 또는 표현할 수 없는 값 또는 누락된 값
- 값이 없는 경우, None으로 데이터를 입력 가능
-
- 데이터 병합
- merge(a,b) : 두 개의 DataFrame을 특정 열을 기준으로 병합(Join)하는 기능
- 결측치 처리
- isnull() : 결측치 확인하는 함수
- fillna(value) : 결측치(NaN)를 채우는 함수
- duplicated() : 중복된 행을 찾을 때 사용하는 함수
- drop_duplicates() : DataFrame에서 중복된 행을 제거하는 함수
- 데이터 병합

Numpy(Numerical Python)
- 다차원 배열 및 행렬 연산 지원 라이브러리
- 과학 계산을 위한 다양한 함수 제공
- 설치 및 import
- pip install numpy
- import numpy as np
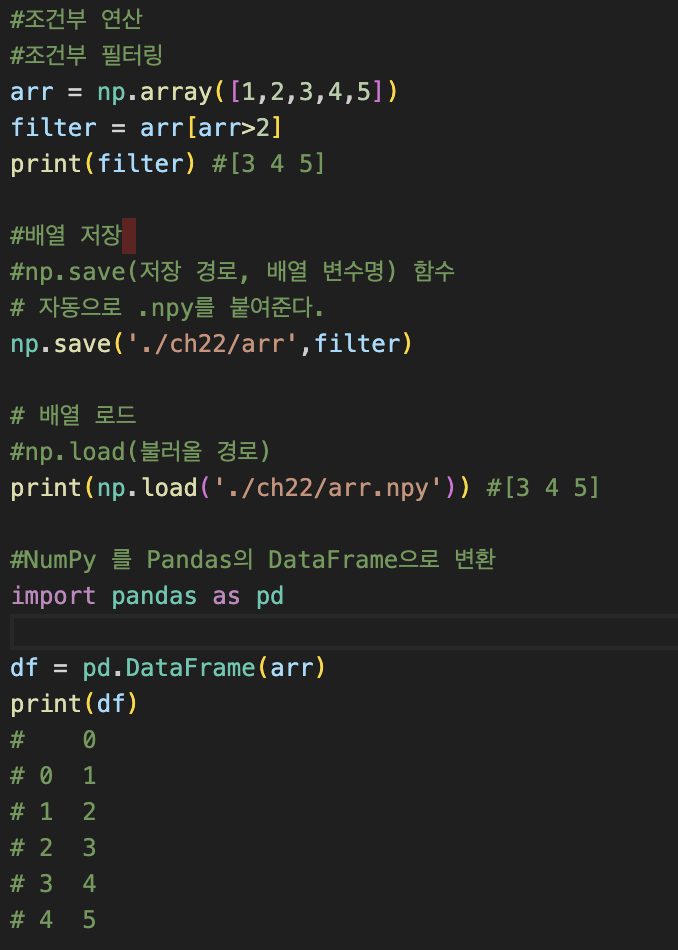
- 배열 생성
- arr = np.array([1,2,3,4,5])
- 배열 속성 확인
- arr.shape : 배열의 모양
- arr.dtype : 데이터 타입
- np.zeros(행,열) : 0으로 초기화된 배열 생성해주는 함수
- np.ones(행,열) : 1로 초기화된 배열을 만들어 주는 함수
- np.full((행,열),값) : 특정 값으로 채운 배열을 만들어 주는 함수
- np.eye(값) : 단위 행렬 함수
- 단위 행렬 : 행렬의 곱셈에서 항등 역할을 하는 특별한 행렬
- 곱셈의 결과가 원래의 행렬을 그대로 유지하는 성질을 가진다.
- 주대각선의 원소가 모두 1
- 주대각선 외의 모든 원소가 0
- 크기는 정사각형 (행과 열의 개수가 동일)
- 단위 행렬 : 행렬의 곱셈에서 항등 역할을 하는 특별한 행렬
- np.random.rand(행,열) : 랜덤 배열 생성 -> float형
- np.random.randint(랜덤 시작 값, 랜덤 끝 값, (행, 열)) : 시작 ~ 끝 범위의 랜덤 배열 생성 -> int형
- 기본 산술 연산
- 요소별 연산 +, *
- arr = np.array([1,2,3,4])
- arr+5
- arr*2
- 요소별 연산 +, *
- 통계 함수
- sum() : 배열 총 합을 구하는 함수
- mean() : 배열의 평균을 구하는 함수
- max() : 배열 중 제일 큰 값 구하는 함수
- min() : 배열 중 제일 작은 값 구하는 함수
배열 연산 -> 브로드 캐스트
선형 대수 연산
- np.dat(a,b) : 배열 a와 배열 b의 행렬 곱을 구하는 함수
인덱싱 및 슬라이싱
- 기본 리스트 인덱싱이나 슬라이싱 방법과 같다


Matplotlib
- 정적, 애니메이션, 대화형 시각화를 만드는 포괄적 라이브러리
- 플롯(plot) : 두 개 이상의 변수 간의 관계를 보여주는 그래프
- 주요 Python 시각화 라이브러리 비교
- Matplotlib : 기본적이고 유연한 시각화 도구
- Seaborn : 통계적 데이터 시각화에 적합
- 설치 및 import
- pip install matplotlib
- import matplotlib.pyplot as plt
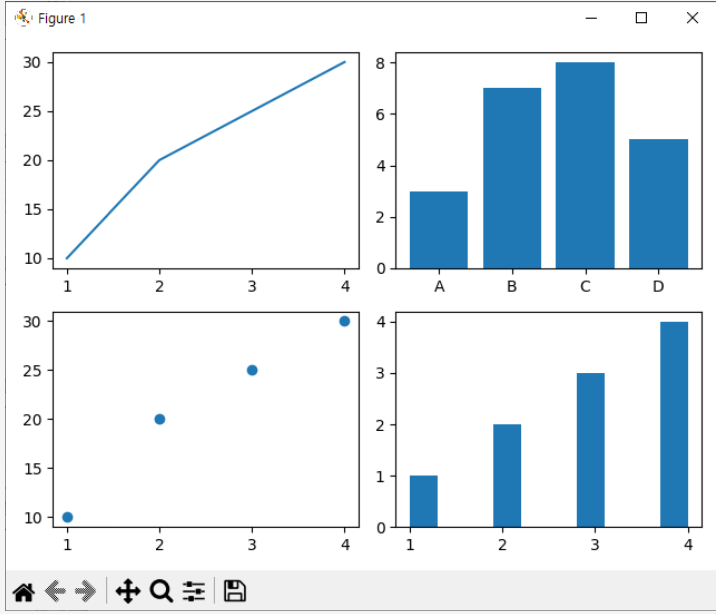
- plt.plot(x,y) : 선 그래프 그리는 함수


- Bar Chart(cartegories, values) :막대그래프 그리는 함수


- Histogram(히스토그램)
- 도수분포표를 그래프로 표현.
- 가로 축은 계급 / 세로 축은 도수(횟수나 개수)
- plt.hist 함수를 사용해서 구현


- Scatter Plot(산점도)
- 두 변수의 상관 관계를 직교 좌표꼐의 평면에 점으로 표현하는 그래프
- plt.scatter 함수를 사용해서 구현


- Pie Chart(파이 차트, 원 그래프)
- 범주별 구성 비율을 원형으로 표현한 그래프
- plt.pie 함수를 사용해서 구현



- Box plot(박스 플롯)
- 수치 데이터를 표현하는 하나의 방식
- 전체 데이터로부터 얻어진 다섯가지 요약 치수를 사용
- 최소값
- 제 1사분위 수(Q1)
- 제 2사분위 수 또는 중위수(Q2)
- 제 3사분위 수 (Q3)
- 최대값
- 이상치(outlier) : 데이터에서 일반적인 패턴에서 벗어난 값으로, 다른 값들과 현저하게 차이가 나는 값


-> 빨간 동그라미한 점이 이상치이다
- plt.subplots(행,열) : 그래프를 그릴 구역을 나눠주는 함수

- 선 커스터마이징






'Python 정리' 카테고리의 다른 글
| 파이썬 - tkinter (0) | 2025.02.11 |
|---|---|
| 파이썬 - 딥러닝 패키지(Seaborn, OpenCV) (0) | 2025.02.11 |
| 파이썬 - 알고리즘(DFS,BFS) (0) | 2025.02.10 |
| 파이썬 - 알고리즘(큐, 스택) (0) | 2025.02.10 |
| 파이썬 - 예외 처리 (0) | 2025.02.10 |