Training set(학습 세트) : 머신러닝 모델을 학습할때 사용하는 데이터 셋
Validation set(검증 세트) : 하이퍼 파라미터(Hyper Parameter) 최적화를 위해 사용하는 데이터 셋
-> 가중치 업데이트에는 영향을 주지 않는다.
-> 학습이 이미 완료된 모델을 검증하기 위한 데이터 셋
-> 학습이 된 여러 가지 모델 중 가장 좋은 하나의 모델을 고르기 위한 데이터 셋
-> 학습 과정에 어느 정도 관여는 하지만 데이터 자체가 학습에 직접적으로 관여하지는 않는다.
Testing set(테스트 세트) : 학습된 모델을 평가할때 사용하는 데이터 셋
-> 모델의 '최종 성능'을 평가하기 위한 데이터셋
-> 학습 과정에 관여하지 않음
-> 보통 Traing set과 Testing set 의 비율을 8:2 즉 80%와 20% 의 비율로 전체 데이터를 나눠준다.

그렇다면 왜 굳이 Training set과 Testing set으로 나누는 걸까?
=> 우리가 원하는 것은 범용적으로 사용할 수 있는 모델이기 때문이다.
- 모든 수집한 데이터들을 Training set으로만 사용하면 해당 데이터들에 한해서 과적합 현상이 일어날 수있다.
- 즉, 학습 데이터에 한해서만 AI가 적응하게 되어서 어떠한 새로운 데이터를 적용한다면 오답일 확률이 늘어나게 되어 해당 문제에 대해서 일반화된 모델이 나올 수 없게 되는 현상이 일어나기 떄문이다.
- 그래서 Traing set을 통해 학습을 하고 학습하고 나온 모델에 대해서 Testing set을 통해서 평가를 하는 과정이 필요하다.
하지만 실제 환경에서 데이터를 수집했을때 데이터의 양이 턱없이 부족해서 학습이 부족하게 될 가능성이 커진다.
그리고 학습하고 Testing set을 통해 검증하는 작업을 계속해서 한다면 Testing Set 데이터에게 모델이 적응하게 되어 이 데이터에게도 과적합 현상을 일으키게 된다.
그렇다면 대체 어떻게 해야하는가? 라는 문제에 직면하게 된다.
이 문제를 해결하기 위해서 우리의 생활에서의 예시를 들어보자면 수능을 치르기 전에 몇 개년 문제집(교과서)을 풀어보면서 학습을 하고, 그 다음 모의고사를 통해서 자신의 지식을 체크하고, 마지막으로 본 시험인 수능을 치르게 된다.
이처럼 모의고사라는 개념으로 Validation이 나오게 된다.
-> 몇 개년 문제집(교과서) : Training set
-> 모의고사 : Validation set
-> 수능 시험 : Testing set 이렇게 생각하면 편할 것이다.
=> 전체 데이터에서 8:2 = (Training set + Validation set) : Testing set으로 나누고, (Training set + Validation set) 데이터를 다시 8:2 = Training set : Validation set으로 나눈다.
=> 즉, Training set으로 학습하고 Validation set으로 검증하고, 마지막으로 Testing set으로 최종 성능을 평가하는 구조이다.
그렇다면 여기서도 "Vailidation set 데이터들에게 또한 적응을 하게 되면 똑같은 문제가 발생해서 결국에는 원점으로 돌아가지 않나" 라는 의문과 데이터가 안그래도 부족한데 단순히 또 나누기만 하면 데이터가 더 부족한 것 아닌가? 라는 의문에 봉착하게 될 것이다. 그리고 뽑은 Validation set이 전부 다 강아지 사진 즉, 편향된 Validation set의 경우도 문제가 생기게 된다.
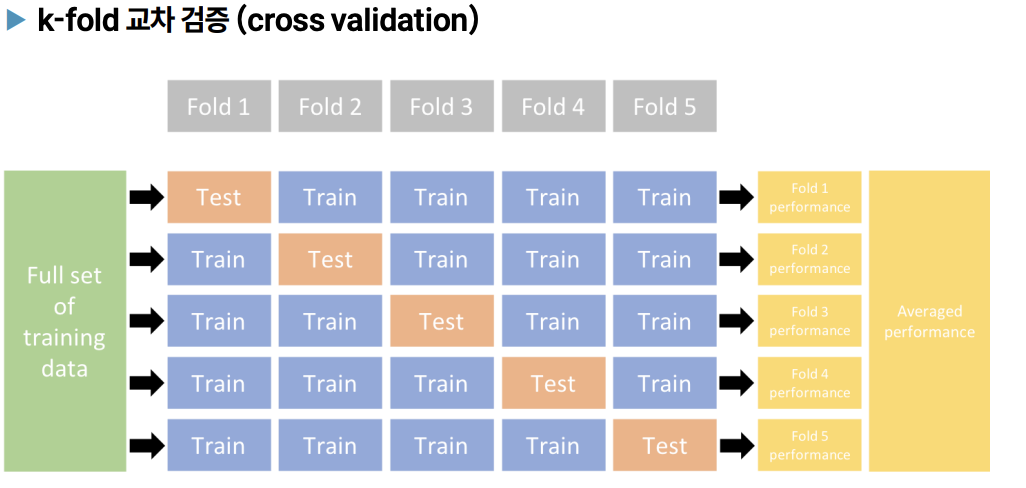
그래서 나오게 된 것이 k-fold 교차 검증 즉 cross validation이다.
k-fold 교차 검증 (cross validation)
: batch_size에 맞게 Test data를 k 등분을 하고 k 등분 중 1개를 Validation set으로 나머지는 Training set으로 학습하는 것을 계속 반복하면서 모든 모델에 대한 평균을 구해서 최종적으로 모델의 성능을 평가하는 방법
-> 모든 모델에 대한 평균 또는 앙상블(합쳐서) 다수결의 원칙(majority vote)에 따라 결과를 뽑기도 함
-> 쪼개는 방식까지가 k-fold 교차 검증이고, 데이터 처리하는 방법에 따라 여러가지 방법을 사용한다.
- 교차 검증의 효과 및 사용 이유
- 모든 데이터 셋을 평가에 활용할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수있다.
-> 특정 평가 데이터 셋에 overfit되는 것을 방지 할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수있다.
- 평가 결과에 따라 좀더 일반화된 모델을 만들 수 있다.
- 모든 데이터 셋을 훈련에 활용할 수 있다.
-> 정확도를 향상할 수 있다. - 데이터 부족으로 인한 underfitting 현상을 방지 할 수 있다.
- 모든 데이터 셋을 평가에 활용할 수 있다.
- 단점 : 반복(Iteration) 횟수가 많기 때문에 모델 훈련/평가 시간이 오래 걸린다.
부트 스트랩핑(Bootstraping) -> 스스로 외부의 도움 없이 라는 의미가 담긴 단어
데이터의 일부를 샘플링하여 여러 개의 학습 데이터셋을 생성하는 방법
-> 데이터 양이 적을때 유용함
- 임의(Random)의 복원 추출(뽑고 다시 넣는 과정) 샘플링의 반복으로 학습데이터가 작을 때 또는 데이터 분포가 불균형일때 사용
- 외부의 도움 없이 (추가적인 데이터 수집 없이) 주어진 샘플의 데이터만을 이용해 학습을 해나가는 것
언제 사용하는가?
확률 분포를 모를때 또는 어떠한 신뢰구간을 알고 싶을 때 주로 사용

AI 기본 용어 정리
- Epochs : 학습 횟수 -> 또는 Step이라고도함
- Batch size : 전체 데이터를 정해놓은 크기에 맞추어서 나누기 위한 데이터의 크기를 정하는 것
- Label/ Ground Truth : 정답 데이터
- Feature : 입력 데이터들
- sample : Feature 쌍 즉 행을 뜻함
- class : 데이터 포인트가 속할 수 있는 범주 또는 그룹 / 주로 분류 문제에서 사용하는 용어
'AI 정리' 카테고리의 다른 글
| Pytorch (0) | 2025.03.24 |
|---|---|
| 행렬(Matrix) (0) | 2025.03.24 |
| 딥러닝 기본적인 모델 유형 (0) | 2025.03.22 |
| Overfitting+ Internal Covariate Shift와 해결 방법 (0) | 2025.03.19 |
| 파라미터(w,b) 초기 값 정하는 방법 (1) | 2025.03.19 |