CNN이란? 이미지, 영상 인식에 특화된 딥러닝 모델로, 패턴과 공간적 구조를 효과적으로 학습
-> 이미지의 공간 정보를 유지한 채 학습을 하는 모델(1D로 변환하는 것이 아닌 2D 그대로 작업)
-> 사람이 여러 데이터들을 보고 기억한 후에 무엇인지 맞추는 것과 유사
CNN의 주요 구성 요소
- 합성곱 층(Convolutional Layer)
- 필터(커널)를 사용해 특징 추출
- 중요한 시각적 패턴 감지(ex. 가장자리, 윤곽)
- 풀링 층(Pooling Layer)
- 특징 맵 크기 축소(-> 다운 샘플링)
- 연산량 감소 및 중요한 정보 유지(ex. 최대 풀링)
- 완전 연결 층( FC: Fully Connected Layer)
- 최종 분류 작업 수행
- Flatten을 거쳐 1차원 형태로 변환 후 출력
- 활성화 함수(Activation Function)
- 비선형성을 추가하여 복잡한 패턴 학습
- 주로 ReLU(Rectified Linear Unit) 사용
- 손실 함수(Loss Function) & 옵티 마이저(Optimizer)
- 예측 값과 실제 값 차이를 줄이기 위해 사용
- 분류 문제에서는 주로 Cross-Entropy Loss 활용
CNN의 일반적인 구조

- 입력 층(Input Layer) : 네트워크에 데이터를 입력하는 역할
- Feature Extractor(특징 추출기) : 하나 이상의 합성곱 층(Convolution Layers)과 풀링 층(Pooling Layers)으로 구성
-> 합성 층 + 풀링 층
- 합성곱 층 (Convolution Layers) : 이미지에서 중요한 특징을 추출하는 층
- 풀링 층 (Pooling Layers) : 특징 맵의 크기를 줄이고 중요한 정보를 강조하는 층
- Classifier (분류기 -FC: 완전 연결층) : 하나 이상의 완전 연결 층(Fully Connected Layers)으로 구성
- 완전 연결 층(Fully Connected Layers) : 특징 추출기 부분에서 추출된 특징을 기반으로 최종 분류 또는 예측을 수행하는 층
- Output Layer (출력층) : 최종 분류 또는 예측 결과를 출력
- 분류 문제에서는 각 클래스에 대한 확률을 출력
- 회귀 문제에서는 연속적인 값을 출력
합성곱 층 (Convolution Layers) : 작은 크기의 필터(커널)을 사용하여 입력 데이터의 중요한 패턴(=특징. ex. 선, 모서리, 텍스처 등)을 자동으로 학습하고 추출하는 신경망(층)
-> 작은 필터(또는 커널)을 사용하여 이미지 전체에 걸쳐 이동시키며, 각 위치에서 필터와 이미지 간의 내적을 계산
Convolution Layers가 생겨나게 된 이유
-> 기존에 있던 MLP(Multilayer Perception) 즉 다층 퍼셉트론으로 이미지를 분류한다고 했을때,
아래와 같이 이미지를 1차원 텐서인 벡터로 변환하고 다층 퍼셉트론의 입력층으로 사용해야 한다.(= 이미지 자체를 평평하게 펼친 Layers(=FC))

하지만 이렇게 1차원으로 변환된 결과는 사람이 보기에도 어떤 이미지였는지 알아보기 힘든 것처럼 기계도 마찬가지이다.
왜냐하면 변환 전에 가지고 있던 공간적인 구조(Spatial structure) 정보가 유실된 상태이기 때문이다.
공간적인 구조가 사라진다면 이미지가 같은 대상이라도 휘어지거나 깊이감, 경계, 패턴 등의 다양한 변형 자체 또한 판별을 할 수 없게 된다.
결국 이러한 문제 때문에 이미지의 공간적인 구조 정보를 보존하면서 학습하는 방법인 합성곱 신경망이 나오게 된것이다.
-> 결국에는 특징을 합성곱을 통해서 추출한 다음에 FC에 넣게 된다.

공간적인 구조란? 거리가 가까운 어떤 픽셀들끼리 어떤 연관이 있고, 어떤 픽셀들끼리는 값이 비슷하거나 하는 등의 정보를 포함하는 것
<Convolution Layers의 역할>
- 특징 추출
- 필터를 통해 입력 데이터에서 특정 패턴(ex. 선, 모서리)을 탐지
- CNN의 초기 계층은 간단한 패턴(edge)을 깊은 계층은 복잡한 패턴(객체 형태)을 학습
- 파라미터 감소
- 입력 데이터 전체를 연결하지 않고, 작은 필터를 사용하기 때문에 학습해야 할 가중치(파라미터) 수가 줄어듬
-> 이 과정을 통해 계산량을 감소시키고 과적합(Overfitting)을 방지
- 입력 데이터 전체를 연결하지 않고, 작은 필터를 사용하기 때문에 학습해야 할 가중치(파라미터) 수가 줄어듬
- 공간적 관계 학습
- 합성곱은 인접한 픽셀 간의 공간적 관계를 유지하며 학습
-> 이미지와 같은 데이터에 적합
- 합성곱은 인접한 픽셀 간의 공간적 관계를 유지하며 학습
<Convolution Layers이 중요한 이유>
- 효율성 : 이미지 데이터의 크기를 줄이고, 특징을 효과적으로 학습
- 로컬 패턴 학습 : 작은 영역의 특징을 탐지하여 객체의 모양과 구조를 이해
- 자동 학습 : 사람이 특징을 정의하지 않아도 CNN이 데이터를 통해 적합한 필터를 학습
Feature Map (특징 맵) : 합성 곱을 통해서 이미지의 다양한 특성을 추출한 결과물
-> 합성곱 결과
ex) 가장자리, 질감 등
Kernel (커널) : 곱셈 연산에 사용되는 작은 행렬 ex) 2x2 , 3x3 등
Filter (필터) : 여러 개의 커널이 모여서 구성된 하나의 필터 ex) 2x2 커널 3개의 채널 = Filter
=>엄연히 말하자면 Kernel ∈ Filter(Filter 안에 kernel이 있다) 하지만 보통 kernel과 filter를 똑같다고 생각하고 둘다 부름
<합성곱 연산 과정>

<필수 조건>
1. Convolution 연산을 적용할 filter(kernel)의 채널 수는 입력 feature map의 채널 수와 같아야한다. -> RGB

2. Convolution 연산을 적용한 filter의 개수는 출력 feature의 채널 수가 됨


-> 입력 데이터의 채널 수와 커널의 채널 수는 같아야 한다.( RGB로 위의 연산의 경우 같다.)
-> 합성곱 연산을 채널마다 수행한 후 결과를 모두 더하여 최종 특성 맵을 얻는다.
-> 위의 연산에서 사용한 커널은 3개의 채널을 가진 1개의 커널 이다.
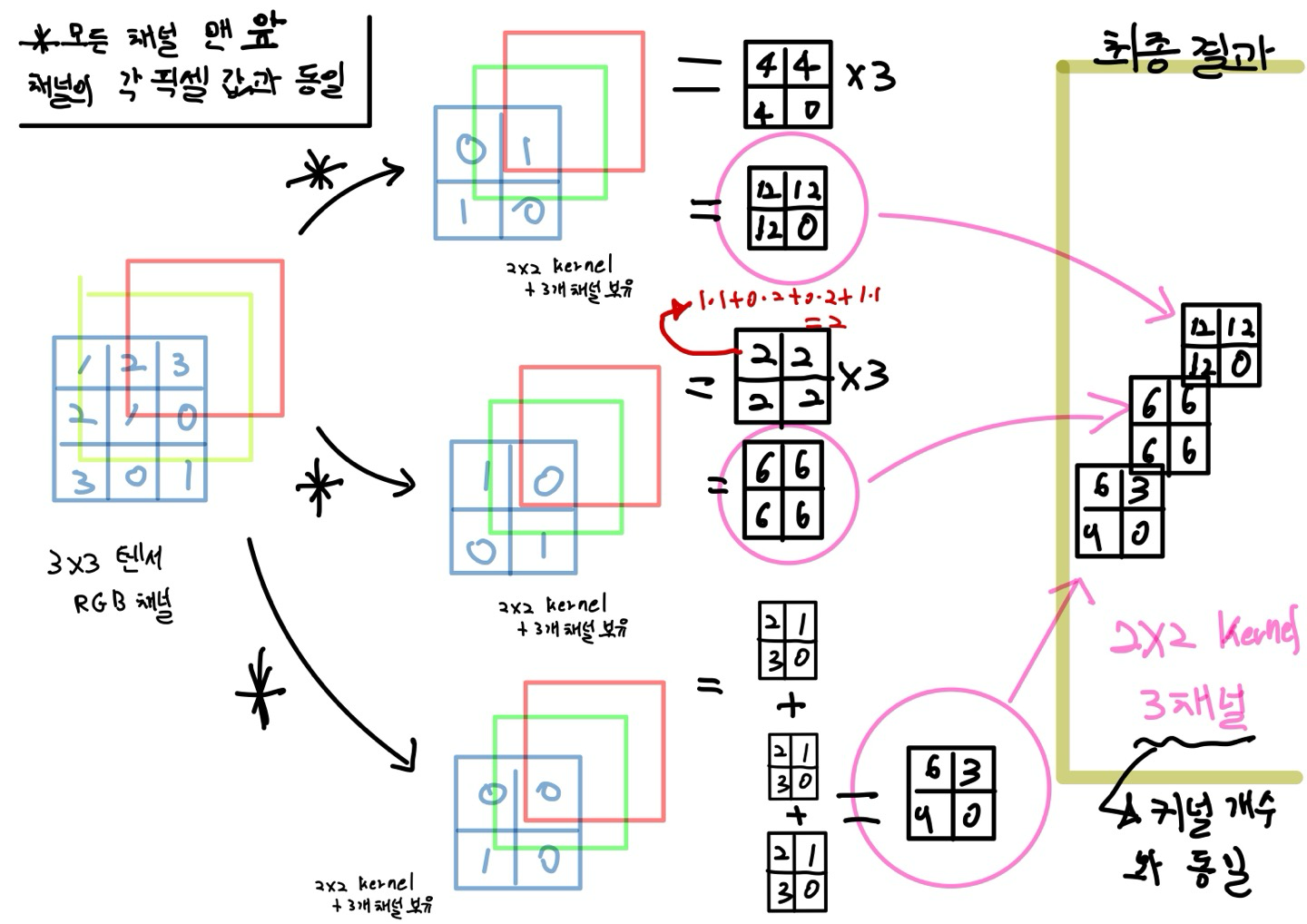
-> 원래는 각 채널마다 다른 가중치를 학습한다.
Padding (패딩) : 합성곱 연산 전에 입력 데이터 주변에 특정 값을 채우는 것
- 주로 출력 데이터의 크기를 조정할 목적으로 사용
- 합성곱을 계속하다 보면 출력 커널 크기가 1*1 되어 더이상 합성곱 연산을 할 수 없게 된다 이러한 경우를 방지하기 위해 사용
- 패딩을 사용하여 데이터 크기를 유지한 채로 다음 layer에 데이터를 전달하려는 것

Stride : 보폭이란 의미로 필터를 적용하는 간격
- 패딩을 크게하면 데이터의 크기가 커지는 반면 stride를 크게하면 출력 데이터의 크기는 작아진다.

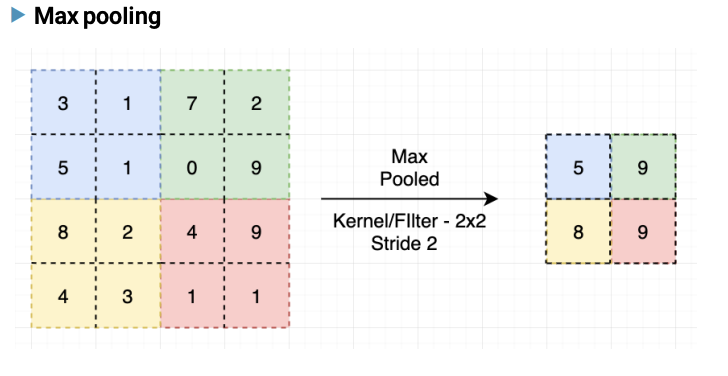
Pooling (폴링) : 특성 맵을 다운샘플링하여 특성 맵의 크기를 줄이는 연산
-> 주로 최대 풀링(Max Pooling) 과 평균 풀링(Average Pooling)이 사용됨
- 학습해야 할 가중치가 없으며 연산 후에 채널 수가 변하지 않는다


합성곱 연산 후 결과 영상(Kernel)의 크기 공식

n : 입력 Feature Map의 크기
k : Filter의 크기(Kernel size)
P(Padding : 정수) : 모서리를 채우는 패딩 수
S(Stride : 정수) : 몇 단위로 이동하는가?
위의 그림을 예시로 계산해 보았을때 (3 + 2*0 - 2) / 1 + 1 = 2 이므로 2 x 2(2바이2) 커널 크기가 생성된다는 것을 미리 알 수 있다.
이제 Feature Extractor(특징 추출기)를 지나치게 되면 즉, 합성곱과 Pooling 작업을 마친 후의
각 픽셀에서 특징이 추출된 Feature Map을 1차원으로 펼치게 되는 FC 과정으로 가게 된다.
Fully Connected Layer
-> Flatten 함수를 통해 모든 픽셀을 1차원 배열로 만드는 작업

이후의 과정은 1차원으로 펼친 FC Layer를 각 픽셀 별로 아래의 Input Layer에 넣어서 순전파 수행
-> 그 후의 과정은 지금까지 우리 원래 알던 MLP(다층 퍼셉트론)의 과정을 통해 순전파를 수행하게 된다.
(-> 지금까지의 과정 다 순전파)
그 후 나머지 손실 함수 -> 역전파 -> Optimizer 과정 -> 파라미터 보정 등의 작업이 다 동일하다.

AdaptiveAvgPooling layer
-> 적응형 AvgPooling Layer로서 어떤 이미지 크기를 넣더라도 AvgPooling Layer의 튜플 값으로 준 (H,W) 값 그대로 이미지 크기가 나오도록한다.


이제 FC Layers 단계에 오기 전까지의 layer 구성 방법에 따라서 여러 가지 모델들로 나뉘게 된다.
-> 즉, CNN의 발전 과정을 다음 장부터 살펴보겠다.
-> AlexNet, GoogLeNet 등
'AI 정리' 카테고리의 다른 글
| 전이학습과 Fine-tunning (0) | 2025.03.26 |
|---|---|
| CNN 발전 과정(1) (0) | 2025.03.26 |
| 딥러닝 아키텍처(Architecture) (0) | 2025.03.24 |
| Pytorch (0) | 2025.03.24 |
| 행렬(Matrix) (0) | 2025.03.24 |