One-Stage Detector : end-to-end 방식으로서 딥러닝 네트워크 하나만으로 Region Proposal + Classification + Localization을 통한 Bounding Box까지 한번에 처리하는 방식
-> 이미지 전체를 한번에 분석
ex) YOLO 계열과 SSD 계열
Backbone(Feature Extractor: 특징 추출기) : 딥러닝 모델에서 기본이 되는 특징(Feature)을 추출하는 신경망을 의미 => Feature Map 생성
-> 즉 입력 이미지를 받아서 주요 특징을 뽑아주는 역할을 하는 CNN 네트워크
-> Yolo 계열과 SSD 계열의 경우 입력 이미지가 GoogleNet, VGG19와 같은 Backbone을 통과해서 Feature Map을 생성하고 그 Feature Map을 사용해 Localization과 클래스 예측함
Confidence score 계산법

- pr(Object) : 물체의 중심 좌표가 그리드에 속한다면 Pr(Object) =1 , 속하지 않는다면 Pr(Object) =0
IoU(Intersection over Union)

- 교집합/ 합집합 뜻으로 Ground truth(실제 Object가 있는 box)와의 합집합 영역을 분모로 하고 교집합 영역을 분자로 한 값
-> 꼭 Ground truth가 아니어도됨
YOLOv1
: 제일 처음 One-stage Detector 계열 모델로, GoogleNet 스타일의 CNN 구조를 BackBorn으로 사용했다.
-> 다만 GoogleNet의 Inception 모듈 대신에 1 x 1 Conv와 3 x 3 Conv를 조합하여 특징 추출


YOLOv1 (You Only Look Once) 수행 과정
CNN을 통과한 최종 Feature Map에 이와 같은 방법을 적용해서 Classification과 Localization을 수행했다.
1. S x S 크기의 그리드 셀 생성
-> 각 그리드 셀은 자신이 포함하는 객체만 예측

2. 각 그리드 셀마다 B 개의 앵커 박스를 생성
-> 일반적으로 2개의 Bounding Box 예측 -> 물체들의 중심점이 겹치는 갯수가 2개의 물체 이상 없을 것이다라고 가정한 것
3. 각 앵커 박스에는 5개의 정보 (x, y, w, h, Confidence score C)가 들어 있다.-> Confidence score(C)는 1 ~ 0 값을 가짐
4. 각 그리드 셀마다 c개의 클래스들에 대한 분류 스코어를 산출한다.
-> Confidence Score과 곱해서 최종 클래스별 확률을 계산



5. 최종적으로 S x S x (B x (5 + c)) 크기의 예측 텐서가 출력
6. 각 클래스에 대해서 NMS(Non- Maximum Suppression) 진행

7. 이제 학습을 계속하면서 손실 함수를 바탕으로 실제 GT(Ground Truth) 값과 비교를 통해서 Anchor Box 크기 조정 및 Classification 학습을 하게 된다. ( 1 ~ 6 반복)
8. 최종 Anchor Box가 Bounding Box가 된다.
(예시는 알아보기 쉽게 이미지로 한것이지만 실제 마지막 Feature map을 봤을 때는 함축적인(많은 정보가 담긴) 이미지라 알아보기 힘들다.)
Yolov1 의 한계점
- 작은 크기의 Object는 감지에 대한 성능이 떨어진다.
->CNN의 최종 Feature map에서 진행하기 때문 - 각 Grid cell 별로 하나의 Object만을 detect함
-> 각 그리드마다 앵커박스 여러개에 대한 데이터가 있더라도 제일 큰 1개만 선택됨
SSD(Single Shot Multibox Detector) -> Yolov1 과 달리 벡터에 P가 없다.
나오게 된 배경 : 작은 크기의 Object는 감지에 대한 성능이 떨어지는 Yolov1의 문제들을 해결하기 위함
-> 여러 Convolution 층의 Feature map에 적용해서 중간중간에 결과를 뽑는 방식
->더욱 다양한 anchor box를 찾아내는 방식

-> 위의 사진을 보면 SSD는 여러 층의 Feature Map에서 객체 검출을 하는 것을 볼 수 있다.
SSD의 특징
- Multi Scale Feature Maps for Detection -> 여러 CNN층의 Feature map에서 객체 검출함
-> 작은 크기의 물체 또한 감지하기에 쉬워짐
->앞쪽 feature map에서 찾을 수록 작은 물체가 detect(감지)되고 뒤쪽 feature map에서 찾을 수록 큰 물체를 감지하기 쉽다.
-> Convolution 과정이 깊어질수록 큰 영역의 이미지를 탐지하고 초반에는 조그만 영역의 객체를 탐색할 수 있다.


- Default Boxex(=Anchor Box) Generation : 6개의 Feature map마다 각각의 가로 , 세로 비가 다르고, 이는 곧 grid cell 크기도 달라진다는 것이기 때문에 6개의 Feature map마다 input image 대비 default box의 크기 비율 Sk를 지정해주는 것
-> 여러개의 Anchor box 생성
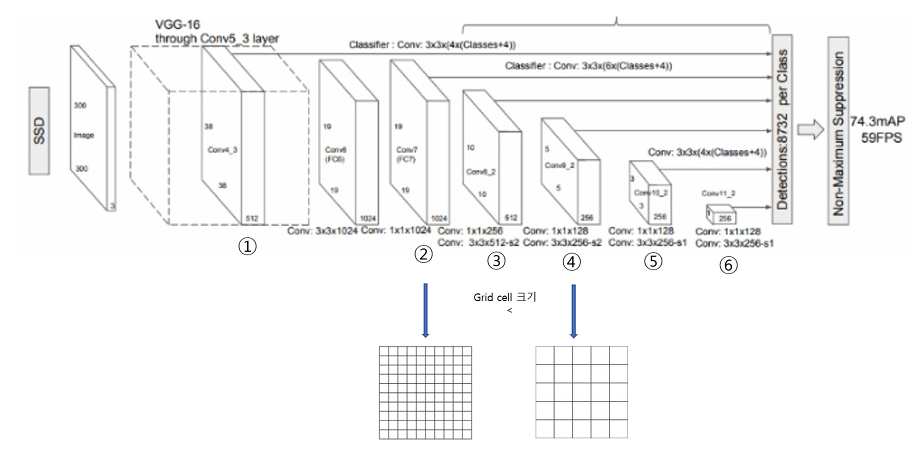

SSD 과정
- SSD는 중간 중간의 Feature map마다 조절한 anchor box를 바탕으로 객체 검출을 진행하는 것 외에는 순서가 YOLO와 달라진점이 없다.
Yolov3 ->anchor box vector에서 P 사용

-> ResNet의 Residual layer을 사용
-> High-level feature map을 upsampling하여 크기를 맞춘 후 하위 level에 있는 feature map과 합친 결과의 feature map들을 가지고 객체 검출을 함으로써 다양한 크기의 객체를 더 잘 예측할 수 있게 되었다.

Anchor Box(앵커 박스) : 객체 검출 (Object Detection) 모델에서 물체의 위치와 크기를 예측하기 위해 사용되는 고정된 사전 정의된 바운딩 박스
-> Anchor box를 사용하면 네트워크가 여러 개체, 다른 크기의 개체 그리고 겹치는 개체를 감지할 수 있다.
-> 여러 데이터들을 기반으로 K-mean(평균)을 통해 앵커 박스 표준 크기들을 정함


앵커 박스를 사용하는 대표적인 객체 검출 모델 정리
- Faster R-CNN
- 이 모델은 CNN기반의 Region Proposal Network(RPN)을 사용하여, 앵커 박스를 통해 후보 영역을 제안하고 이를 바탕으로 객체를 검출
- YOLO (You Only Look Once)
- YOLO 모델은 한 번의 전방향 패스 즉, 마지막 feature map에서 객체를 검출하는 방식으로 동작하며, 이미지 내 그리드 셀마다 고정된 앵커 박스를 사용하여 객체의 위치와 크기를 예측
- YOLOv3와 같은 버전에서 앵커 박스 개념이 사용
-> YOLOv3이후로 SSD 같은 Anchor Box 방식 채용
- SSD
- 여러 feature map에서 다양한 Anchor Box를 생성 후 객체 검출
https://wikidocs.net/142280 -> SSD 자료
https://deep-learning00.tistory.com/15 -> Yolov1 자료
https://wikidocs.net/163613 -> Yolov3 자료
'AI 정리' 카테고리의 다른 글
| Transformer (0) | 2025.03.31 |
|---|---|
| RNN(Recurrent Neural Network : 순환 신경망) (0) | 2025.03.30 |
| CNN 발전 과정(4) - two-stage Detector(R-CNN계열) -> object detection (0) | 2025.03.29 |
| CNN 발전 과정(3) - VGGNet, ResNet -> Classification (0) | 2025.03.27 |
| CNN 발전 과정(2) - AlexNet, GooGleNet -> Classification (0) | 2025.03.27 |